The Scaling Dilemma: How Data Teams Grow, Adapt, and Thrive
In recent years, I’ve been fascinated by the rapid scaling of data teams within organizations. It’s a journey that mirrors the growing importance of data in our business landscape, and I think it’s worth exploring in depth.
Let’s start at the beginning. Many companies initially approach their data needs with a single, versatile professional. This person is often described as a “Swiss Army knife” of data, handling everything from data ingestion and integration to creating reports for decision-makers. It’s an efficient setup… at first.
But as companies realize the potential of data-driven decision making, the demands on this lone data professional quickly escalate. More data, more complex analyses, more stakeholders to satisfy — it’s a recipe for bottlenecks and burnout.
This is where we see the emergence of specialized roles. Data Engineers step in to build robust data pipelines and manage the infrastructure. Data Analysts take on the task of diving deep into the data to extract meaningful insights. Data Scientists bring advanced statistical and machine learning techniques to solve complex problems.

It sounds great in theory, right? Specialized skills for specialized tasks. But here’s where it gets interesting — and challenging.
As these teams grow, they often face a number of hurdles:
- Knowledge Silos: With specialization comes the risk of fragmentation. The holistic view of the data lifecycle can get lost as each professional focuses deeply on their area of expertise.
- Communication Gaps: More team members mean more potential for misunderstandings and missed connections. Ensuring everyone’s on the same page becomes a significant challenge.
- Responsibility Blur: When roles overlap, as they often do in data work, it can become unclear who’s responsible for what. This can lead to tasks falling through the cracks or, conversely, duplicate efforts.
- Troubleshooting Nightmares: When something goes wrong (and in the world of data, something always goes wrong eventually), pinpointing the issue becomes exponentially more difficult. Is it a problem with the data pipeline? The analysis methodology? The visualization layer?
- Data Quality Concerns: As data volumes grow and pass through more hands, maintaining consistent quality becomes a significant challenge. And let’s be honest, data quality issues can wreak havoc on downstream processes and decision-making.
- Trust Issues: This is a big one. I’ve seen situations where a single data discrepancy can shatter trust in the entire data ecosystem. Rebuilding that trust? It’s a long, uphill battle that no one wants to fight.

But it’s not all doom and gloom. These growing pains come with significant opportunities:
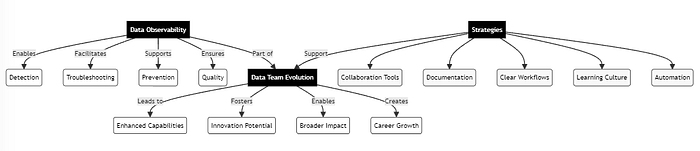
- Enhanced Capabilities: Larger, specialized teams can tackle more complex data projects than ever before. We’re talking about analyses and insights that were pipe dreams just a few years ago.
- Innovation Potential: More minds working on data problems means more potential for innovative solutions and approaches.
- Broader Impact: Expanded teams can handle more projects simultaneously, increasing the organization’s capacity for data-driven decision-making across the board.
- Career Growth: As teams expand, new leadership and specialized roles emerge, providing career advancement opportunities for team members.
So, how are organizations navigating these challenges and opportunities? I’ve seen a few strategies that seem to be working:
- Investing in Collaboration Tools: Platforms that facilitate seamless communication and knowledge sharing among team members are crucial.
- Emphasizing Documentation: Encouraging thorough documentation of processes, decisions, and insights helps preserve institutional knowledge and breaks down silos.
- Implementing Clear Workflows: Well-defined processes for data handling, analysis, and reporting ensure consistency across the growing team.
- Fostering a Learning Culture: Continuous learning and skill development keep the team adaptable and innovative.
- Embracing Automation: Leveraging automation tools for repetitive tasks frees up team members to focus on higher-value activities.
One concept that’s gaining traction is the idea of data observability. It’s an approach that aims to provide greater visibility into the entire data ecosystem, helping teams detect and resolve issues quickly, and even prevent problems before they impact end-users. I think we’ll be hearing a lot more about this in the coming years.
The evolution of data teams is an ongoing process, and I’m sure we’ll see more changes as technologies advance and business needs evolve. What’s your experience been? Have you seen your organization’s data team grow and change? I’d love to hear about the challenges you’ve faced and the strategies that have worked for you.
